Torch To JAX
To say that there is an ongoing war in deep learning between the PyTorch and JAX ecosystems would be an exaggeration. PyTorch is winning. Deep learning research feels like Groundhog Day but you wake up each morning to another "How-To" or paper written PyTorch.
This balance makes sense because PyTorch is to JAX what JavaScript is to Rust: PyTorch just works, there's a library for everything, and there's N+1 tutorials for any experiment you might be tempted to try. And with NVIDIA contributing so intensely to the PyTorch CUDA kernels, the Force is strong with PyTorch.
But as everyone swallows their Bitter Lesson pills, the truth emerges at scale: JAX >> PyTorch. The reasons why are documented, and I won't address them here, but the bottom line is that if you look at the important AI labs, you'll notice that most of them use JAX in their production models in one form or another: xAI, Anthropic, Google DeepMind, Midjourney.
TLDR; if you work at scale, you want the advantages that JAX affords you. PyTorch is for small models. Small models are no fun. You want to have fun don't you?
Cool, but why is this blog titled "Torch to JAX"? Good question. I have a tendency to use my blog not just as writing repository but as a place to refactor FAQs that I get from friends. This blog seeks to answer one common question: "Dane, I'm sold, but I need to convert this PyTorch model into JAX!" I'm omitting most of the code but the outline is below.
The first principles of converting from PyTorch to JAX are:
- defining equivalent models in PyTorch and JAX
- porting all PyTorch parameters and hyperparameters over to JAX
- saving your JAX model if you so desire
In step 1 we define the models:
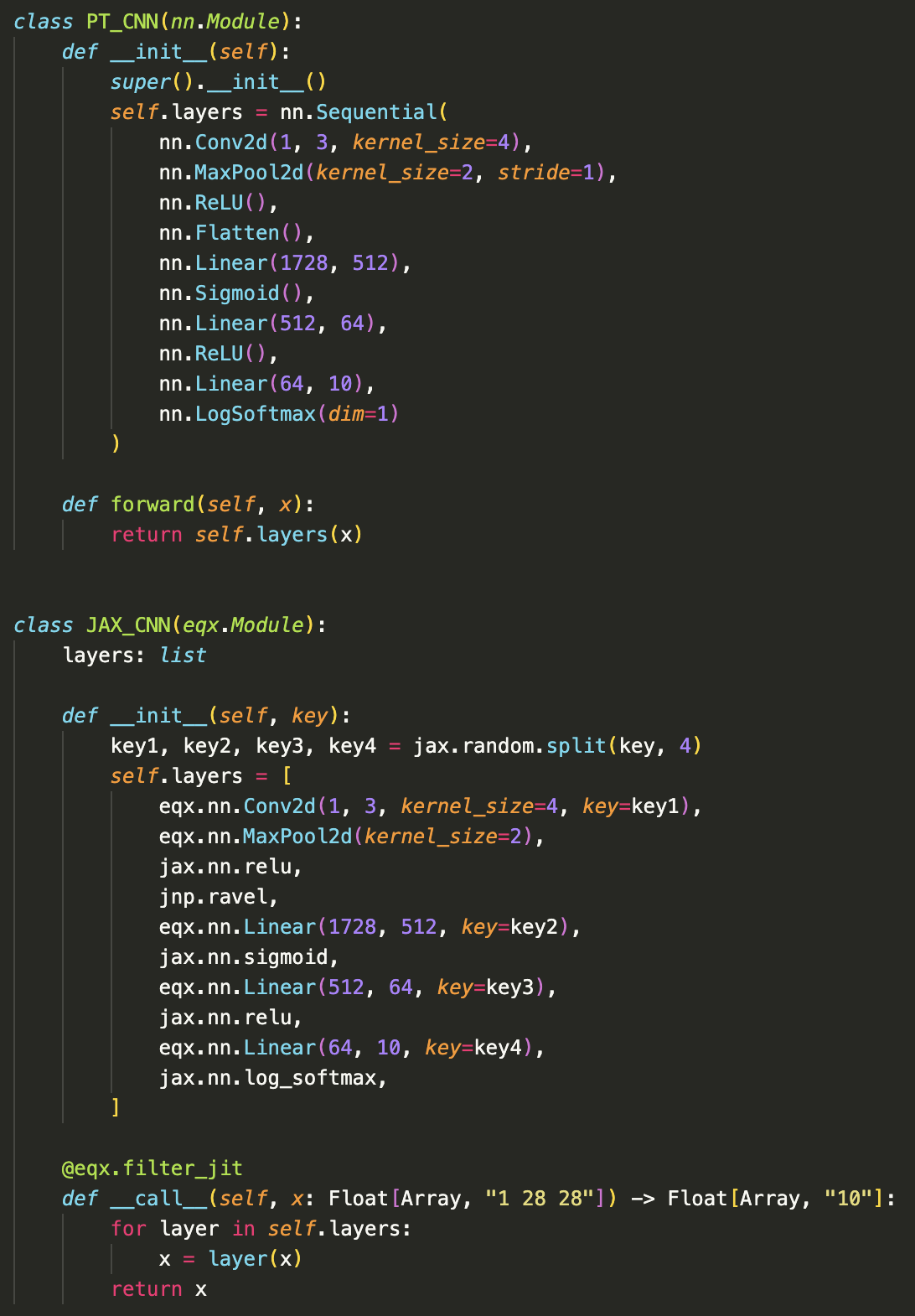
In step 2, we load our PyTorch model and convert it to JAX. Let me save you some trouble: the Flax/Haiku ecosystem is garbage, and you should use Patrick Kidger's Equinox for neural network work as it provides fantastic methods for performing model surgery . There are two advantages to Equinox. 1) It's better and 2) Patrick is cool.
YMMV here, and as you get to more complicated models you'll need to write custom weight transfer code. However, the only principle you need to remember is that all tunable parameters must be shared.
You can check that you've successfully ported over the weights by passing an input through both the old PyTorch and the new Equinox model and check if the outputs are identical. Barring changes in the weight precision, the outputs should be equal.
In step 3, you can save the JAX model however you see fit. For small models, this is just one file, but for larger files you'll have a few tensor shards you'll need to port. At this point, you're in JAX world. Also recall that JAX does not allocate memory until the JIT compilation happens, so you're really just swapping around pointers.
If you're new to ML engineering, a simple project would be to pick an existing module (like CLIP) that exists in HuggingFace transformers or diffusers, port it to Equinox, upload the weights, and make a PR. Do this twice and you'll learn a great deal, as well as significantly speed up performance (I notice at least a 7% speed up in inference across different backends and a 2-3x speed up for training!)
Go forth and prosper!